在数字人技术快速发展的当下,生成效率依旧是行业亟待解决的核心难题。商汤科技依托在生成式AI和多模态交互领域的扎实积淀,研发出实时语音驱动数字人技术——SekoTalk。借助多维度的创新技术手段,SekoTalk大幅提高了数字人视频的生成效率,在8卡服务器环境中,生成速度可达25 fps,首帧延迟仅3.5秒,在行业内率先达成实时生成的目标。此外,SekoTalk还能够支持多人场景、多语言环境下的口型精准适配,以及超长时间的稳定生成效果。这一技术突破了数字人发展过程中的性能限制,为数字人实现大规模、实时化的应用拓展了更多空间。
SekoTalk今年8月上线,应用在商汤Seko、如影数字人等产品中,已助力用户创作出数十万部作品,并诞生了全网播放量超2000万播放的爆款作品。
生成效率是数字人走向实用化的关键,而实时性又是生成效率的北极星。SekoTalk通过模型蒸馏,模型结构优化,以及模型与系统的协同设计,在保证生成质量的前提下,实现推理效率的跨越式提升。
和其他方案比起来,SekoTalk的性价比优势十分突出:开源模型生成一段5秒的视频往往要超过十分钟,商用闭源模型生成5秒视频通常也需要1到10分钟左右。而SekoTalk在8卡服务器上的生成速度能达到25帧每秒,就算把SekoTalk和多模态模型结合使用,整个系统的首帧延迟也能低至3.5秒。
Phased DMD分布匹配蒸馏技术,无限逼近base模型效果:
以往在扩散模型蒸馏方面的实践表明,低步数生成质量往往受限于等效模型的容量。而当前主流的SOTA视频生成模型已充分验证混合专家(MoE)技术在扩散模型领域的显著潜力——在不增加推理成本的前提下,能够有效提升等效模型容量,从而带来更优的性能表现。不过,MoE技术在扩散模型蒸馏场景中的应用尚未得到深入探索。商汤科技团队研究发现,若直接将分布匹配蒸馏(DMD)应用于MoE模型,会导致生成视频的运动流畅度与指令遵循能力下降。针对这一问题,团队提出了Phased DMD技术,将去噪过程构建为多阶段的MoE模型架构。该技术不仅能原生适配MoE模型,对于非MoE的教师模型,也可通过蒸馏将其转化为MoE学生模型。这一创新显著增强了蒸馏后模型生成内容的动态效果与多样性,使SekoTalk在推理开销降低25倍的情况下,仍能保持教师模型原有的肢体运动自然度与情绪表达能力。除了在SekoTalk上的应用,Phased DMD还对开源社区常用的基础模型进行了蒸馏优化并反馈至社区,相关优势已获得开源社区的认可,进一步验证了该技术的通用性与有效性。
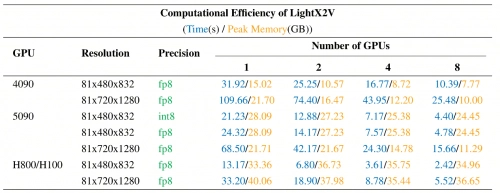
LightX2V采用与模型协同设计的方式,可支持低资源环境下的部署。作为商汤科技开源的行业内首个能实现实时视频生成的推理框架,LightX2V在模型与系统的设计阶段,就将低比特量化感知训练、稀疏注意力等原生优化手段融入其中,再搭配自研的“SPARSE+NVFP4+低比特通信”高效注意力算子,使得模型在完成训练后即可直接进行低资源部署。
从测试数据来看,在不同GPU硬件环境下,LightX2V均能实现 SekoTalk 的高效推理,为不同场景的落地提供灵活支撑。
传统数字人技术在处理多语言、多人交互的复杂场景时,常出现口型与语音匹配不准的问题。SekoTalk通过一系列创新设计,实现了从单人口形到多人互动的高度精准的声形同步。
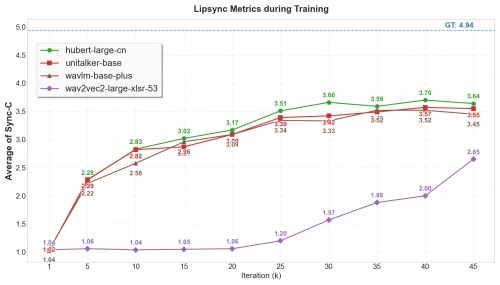
在2D数字人生成领域,部分研究工作仍采用早期wav2vec2系列预训练语音编码器实现角色驱动。商汤团队依托在3D数字人语音驱动技术UniTalker上积累的算法经验,意识到语音编码器的选型对数字人驱动效果起着关键作用。 为此,研究团队针对wav2vec2、hubert、wavlm、whisper等多款语音编码器,开展了2D数字人驱动场景下的性能对比探究。结果显示:即便采用多语言预训练的wav2vec2-large-xlsr-53模型,其在英语口型驱动的精准度及多语言泛化能力的定量评测中,表现仍不及其他几款编码器。 通过系统的消融实验验证后,SekoTalk最终选用了本次探究中性能最优的音频编码器;结合规模化训练优化,该模型在中英文、多小语种场景,以及日常对话、说唱等多样化表达情境中,均实现了高精度的数字人驱动效果。
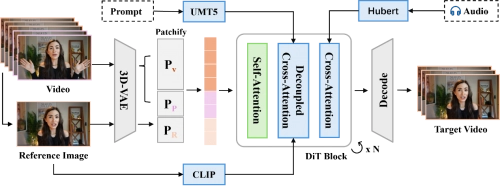
音视频帧率解耦,防止细节丢失:主流视频生成模型采用“1+4N”时序压缩机制,为达成与视频帧的精准同步,SekoTalk对音频处理分支展开了细致优化。它创新性地将视频帧率(16-25fps)与语音特征帧率(50fps)进行解耦,规避了传统下采样方式导致的口型细节丢失问题,让音频能够和任意帧率的视频在时序上实现对齐,确保音频与画面的高质量同步。
多人场景高度可控:借助良好的模型泛化能力和创新的掩码注意力机制(Attention Mask),SekoTalk可在多人对话场景中,独立、精准地控制每个角色的口型与动作,输出自然流畅的群组互动效果,拓展了技术的适用场景和应用潜力。
高效能、低成本的语音模块:在文生视频领域,人们常利用文本条件的Classifier-Free Guidance(CFG)来优化视频生成质量;而在数字人生成领域,过往研究也采用类似思路,通过语音条件的CFG提升口型驱动的精准度,但这会比仅用文本条件生成视频增加50%的计算成本。此外,文本条件的CFG往往会导致生成画面过饱和,同理,语音条件的CFG在提高口型驱动准确性时,也常使生成的人脸画面显得夸张且不自然。商汤团队提出,通过优化语音注入模块的设计,能够从根本上解决这一问题。借鉴DiT的设计理念,研究团队在语音模块中引入了Adaptive Layer Normalization(AdaLN),并以可学习参数的注入方式替代传统的Linear Projection,在保证生成表现力的基础上降低了计算开销。经过这些优化,SekoTalk模型无需依赖语音条件的CFG,就能实现精准的嘴形驱动。这一改进不仅减少了计算成本,还避免了因使用语音条件的CFG而需在口型准确性与脸部画面自然性之间做出权衡的问题。
在生成长视频时,画面色彩漂移和人物ID不一致,一直是行业的重要挑战。SekoTalk提出混合参考图注入等方案,有效平衡动作多样性与画面稳定性。
混合参考图注入策略,兼顾“段内稳定”与“段外泛化”:通过在训练阶段随机选择片段内、外的参考图,并辅助标志位指示参考图来源,使模型同时掌握了“段内稳定”与“段外泛化”两种能力。在推理时灵活切换,有效兼顾了动作多样性与画面稳定性。
高低语义特征联合注入,加快模型收敛速度:采用“高语义特征+低语义特征”的双通道注入机制,利用不同层级的语义信息引导模型,这不仅加强了人物ID的一致性,还加速了模型的收敛。
分离式Patchify编码,高保真条件注入:将加噪视频、参考图、前序帧等不同类型的特征交给独立的Patchify分支处理,使模型注意力更容易区分并理解多源信息。这不仅增强了长视频生成中的人物一致性,还提升了续写的连续性与稳定性。
SekoTalk在隐空间续写的效率优化方面表现突出,能保障续写流畅度:具体而言,它在时序维度融入前序帧特征,直接复用前一生成片段末尾的隐空间特征,省去了传统方案里“解码-再编码”的多余步骤;同时结合层级化KV缓存与因果注意力机制,既保证了续写的稳定性,又显著提高了长视频生成的推理效率。
SekoTalk的技术价值已通过实践得到验证。作为首个支持2人以上对口型、生成2分钟长视频的免费技术体验平台,其在线体验平台已产出大量作品,SekoTalk模型也已集成到Seko、如影数字人等产品中使用。另外,SekoTalk实时版在情感陪伴、在线教育、专业咨询领域的实时交互案例,也体现出它推动数字人迈向更自然、智能、实时的未来的潜力。